Tech
Stephen Batifol
Apr 20, 2022
Machine learning at Wolt: our journey towards MLOps
Wolt serves millions of customers and we partner with tens of thousands of venues and more than a hundred thousand courier partners. Like many companies, to help us scale sustainably we use machine learning to make predictions in crucial paths of the user experience. And the fact that we’re building a logistics platform opens up various interesting opportunities to use machine learning models for when optimising our processes and operating models. (If you’re interested in our algorithm, check our transparency page!)
At Wolt, we use machine learning for various core business needs. Our machine learning models help us improve the customer experience for our end-users, allows us to improve the delivery experience of the courier partners on our platform and provide us with deeper insights into key metrics we measure. As an example, we use machine learning to estimate things like how long will it take for a restaurant to prepare the customer’s food order or how long will it take for a courier partner to deliver it to the customer. So it’s crucial that our models are performant and can scale with the demand.
Recently our team has been focusing on building our next-generation machine learning platform. It all stemmed from the fact that the way our data scientists were deploying models was not homogeneous, which made it hard to provide central services. So the goal was to make it easier to deploy machine learning models into production. Let’s see how it all went down…
Our journey towards MLOps
Wolt is a data-driven company and to thrive we need data to be collected from all areas of the business, in a timely and accurate manner, and for relevant data to be available for those at Wolt who need it, sometimes even for everyone at the company. Two years ago, we started building our Core ML and Data Engineering team at Wolt. The vision of our team is to make Wolt’s data available to the rest of the company, and to ensure data is used in the most value-generating way through machine learning and data products.
A lot of what our team does circles around MLOps, which is essentially all about enabling our data scientists to deploy, run, monitor and maintain machine learning models efficiently and conveniently. This is a fairly new concept at Wolt, and so it’s been a big learning curve for us all.

We started this journey by defining the goal — we wanted to make it possible for data scientists to deploy models into production using common infrastructure, in our case built on top of Kubernetes. This meant building a standardised solution for large scale machine learning and getting teams on-board to actively contribute to its maintenance.
Building the infrastructure was a big process that took almost a year. First we analysed potential tools we could use. A key part of this was discussions with our data scientists — understanding their needs, wants and preferences in regards to the tools to ensure we’re focusing on the right things. Finding the right tools that make sense and work for us and deploying them took a big chunk of the time as well. We ensured a consistent feedback loop and rounds throughout the process to ensure we’re on the same page with things, and that our tools solve our problems in the right ways.
Some clear decisions stemmed from the analysis and discussions. We decided that it would be beneficial to be able to easily deploy models on Kubernetes for real-time inference. While Kubernetes is a system that is capable of doing many things, it’s also complex to understand. We needed an ML-Framework that builds on the best of Kubernetes, but at the same time doesn’t require Data Scientists to become Kubernetes-specialists on top of their daily work.
To make that possible, we decided to use Seldon-Core as our deployment framework for real-time models. We chose Seldon-Core for a series of reasons, most importantly because it’s open-source and allows us to contribute in case we need to. Moreover, it builds on Kubernetes and follows the V2 Data Plane inference API which proposes a predict/inference API independent of any specific ML/DL framework and model server.
The benefits of using an ML-Deployment Framework
As stated, the overall purpose was clear: to create a common way of working and deploying machine learning models, to create tooling that saves time, and makes the life of our data scientists effortless and efficient so they can focus on the right things.
But let’s look at the benefits a bit more closely in how we approached the problem:
1. Model lifecycle
At the core of the model was allowing engineers to have end-to-end machine learning models, going from experimenting ideas to deploying models. At the same time we wanted to make it possible for them to do online shadow mode, A/B testing, and canary deployments without having to write additional code.
We also decided to provide a service that automatically updates the models. This service is responsible for loading models, evaluating them based on given metrics and informing engineers when the model has been successfully deployed.
The end goal of this service is to be able to automatically auto-retrain models, and auto-deploy them when needed. Either when we detect a decline in performance or based on other criteria defined by the engineer.
2. Monitoring
We wanted to make it possible to see and know what’s happening with the deployed models. This covers both models that are deployed in production and models that our teams are currently experimenting with. Being able to automatically monitor each model is something that’s crucial for the success of machine learning for us as it allows us to compare the performance of different models. Also make it possible to monitor software engineering metrics such as latency, errors, requests per second but also monitor the predictions of the different models. The latter can be very useful if you want to compare the performance of two different models, one main model and one running in shadow model — this way you can test a new model without affecting the live deployment.
3. ML Framework agnostic
We wanted to leave the choice of framework to the engineers that are building the models. In the future, we might focus only on specific frameworks for performance reasons, but we prefer a framework that leaves this choice to us. For example our data scientists can build ML models with most of the major ML frameworks that exist such as XGBoost, SKLearn, Triton, MLFlow Server, Tensorflow Serving, they all run on this infrastructure.
4. Standardised deployments
By making every deployment standardised, we can reuse our well codified continuous integration-patterns which in the end makes it easier to understand what’s happening behind each model. This is something that can be useful for on-call engineers, for example.
How we’ve deployed models until now
Until now, our data scientists not only had to build their machine learning model, but have had to write their own API, create the routes needed and add monitoring for each model and ensure that the deployments would be scalable and monitorable. As discussed… reinventing the wheel, every time.
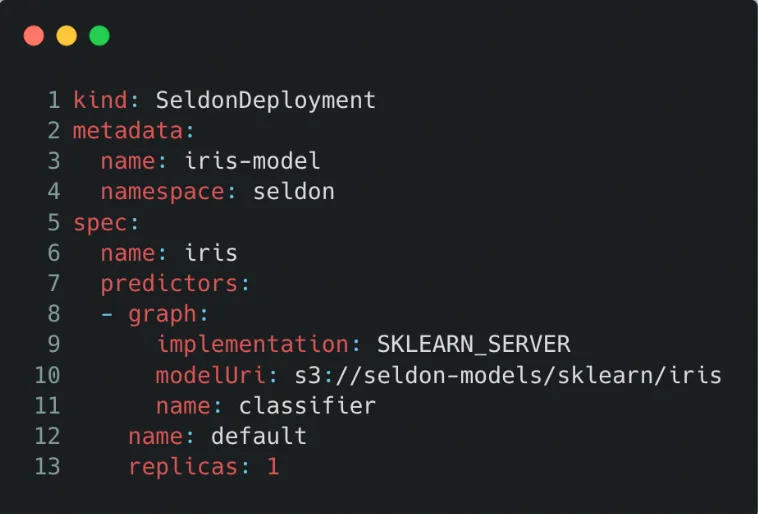
With the new system, using Seldon-core allows us to abstract away a lot of complexity — engineers don’t need to define different routes, add monitoring, configure logging and the like. Here’s an example of how a basic deployment can be defined. It loads a scikit-learn classifier model stored on AWS S3. Once deployed, the spec below will create a deployment with REST and gRPC routes and with monitoring out of the box.
Introducing our new model
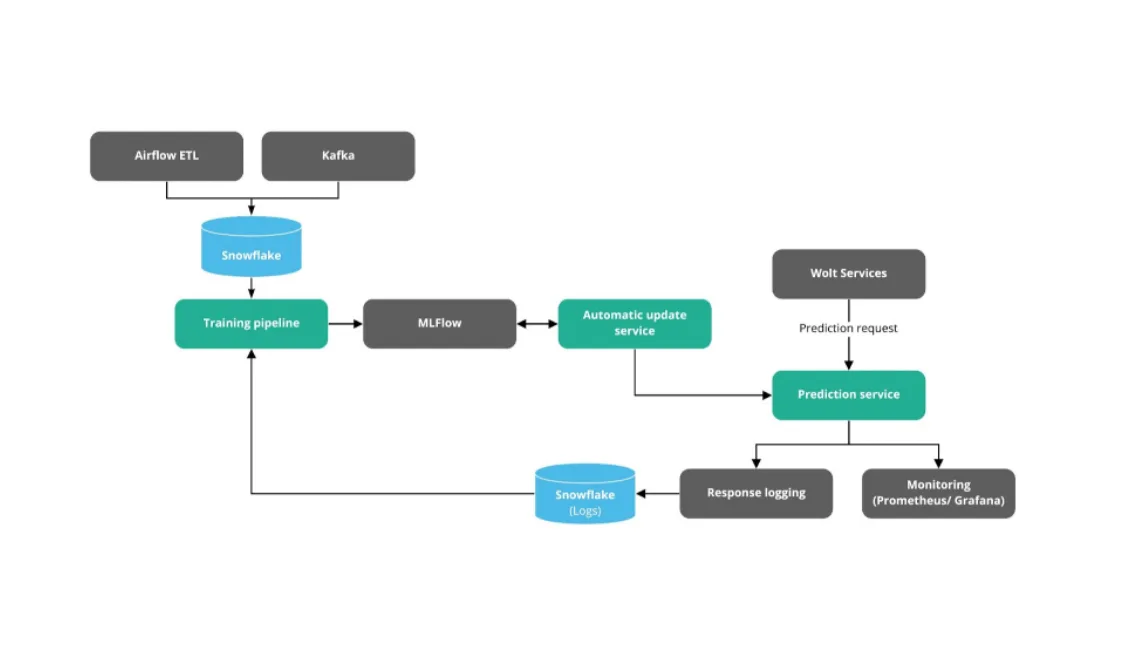
Here we see what the new model looks like as of today. It’ll for sure evolve with time but this is what we will build everything on top of. Here’s an overview of the new model:
Model training pipeline: Pipeline that trains the models with different features, usually written in Python. We also deployed something on top of Kubernetes to allow everyone to train models on our infrastructure.
MLFlow: Essentially, where we store metadata for models. Also, how we’ll know which model is running in production, track our experiments, and so on.
Automatic update service: Service that updates models when a new version is stored in MLFlow. It’ll also check if the model has better performance than the one running in production in the future.
Prediction Service: Service created with Seldon that receives different requests from which we want to predict something from. It can receive requests in different formats and from different services.
Response logging: Saves the predictions from our models so that we can improve it later in the future.
As a result of this new infrastructure, we’re expecting to reduce the overhead and the time needed for deploying models, and hopefully will see more models in production!
Next steps and learnings from the process
As mentioned, we’re now working on deploying a way to train models in our infrastructure. That will allow us to have a better integration with the rest of our services and also make it easier for data scientists to automate parts of their workflows. Other pieces of Wolt will be used in the ML infrastructure such as quality monitoring and experimentation. By doing so, we’ll be able to make sure that data isn’t drifting for example. It will also allow everyone to create experiments to test their ML models. Excited to see what the future holds for this.
This whole process has been a great learning experience of working with a variety of teams — from platform, to data scientists to data engineers. It’s been crucial to have check-points to ensure you all have the same vision in mind, as building a new framework is a big journey and impacts a lot of teams.
If you’re doing something similar in your organisation, my one tip would be to stay as close to your customer (the teams you’re helping out) as possible. By defining how you can make their lives as easy and smooth as possible. And when you’re deep in your project, remember which parts are important to your stakeholders to know, and which ones aren’t. Not everyone cares about the behind the scenes as much as you do!
If you found this article interesting, you also might like this talk “Scaling Open Source ML: How Wolt Uses K8s To Deliver Great Food to Millions” that I did with Ed Shee from Seldon at KubeCon 2022— check it out!